
If you haven’t read part one yet, please read that first!
In this post, I’ll be continuing building on part 1 with GROUP BY, HAVING, ORDER BY, and INNER JOIN, with examples to demonstrate each one.
GROUP BY
GROUP BY does what it sounds like – it groups your results together by a certain column’s values (or multiple columns’ values).
GROUP BY is particularly useful with COUNT. For example, if I wanted to count how many fruits of each color there are, I could do:
SELECT color, COUNT(DISTINCT name) AS "# of fruit types"FROM fruitsGROUP BY color;
| color | # of fruit types |
| red | 3 |
| yellow | 4 |
| green | 1 |
| blue | 1 |
Note that I included ‘color’ as a column in my SELECT phrase; otherwise, I would have just gotten back the second column above with no context!
And if I had not included the GROUP BY phrase in the above query, I would have gotten:
| color | # of fruit types |
| red | 1 |
| yellow | 1 |
| red | 1 |
| yellow | 1 |
| green | 1 |
| yellow | 1 |
| blue | 1 |
| red | 1 |
| yellow | 1 |
Not very useful.
HAVING
The main difference between ‘having’ and ‘where’ is that you can use aggregate functions with having. That includes count, sum (SUM), average (AVG), minimum (MIN), and maximum (MAX). To build on the previous example, let’s see what it would look like if we wanted to see only colors that had more than 1 fruit of that color.
SELECT color, COUNT(DISTINCT name) AS "# of fruit types" FROM fruitsGROUP BY colorHAVING count(DISTINCT name)>1;
| color | # of fruit types |
| red | 3 |
| yellow | 4 |
You can also use the names you’ve defined earlier for those aggregate functions, so we could also do HAVING "# of fruit types" > 1;
Learn more about having and see more examples on sqltutorial.org.
ORDER BY
The last item in your statement, you can choose whether to receive your results in ascending (ASC) or descending (DESC) order. Ascending is A to Z, or the lowest number to the highest number. Descending is Z to A, or the highest number to the lowest number.
Much like with ‘having’, you can use aggregate functions, or reference those you used in your ‘select’ query.
SELECT color, COUNT(DISTINCT name) AS "# of fruit types" FROM fruits GROUP BY color HAVING count(DISTINCT name)>1 ORDER BY "# of fruit types" DESC;
| color | # of fruit types |
| yellow | 4 |
| red | 3 |
INNER JOIN
JOIN is used to combine multiple tables together. There are many different types of ‘join’ – check out more information on w3c’s site.
With inner join, you’re only joining parts of the table that match up across a certain set of values.
First of all, why might you want to join two tables? Well, tables are split up so there’s not too much info in any one table. If your company tried to track every piece of customer information along with every action they take in your app, for example, that would be an enormous table. Meanwhile, much of it would be blank as some customers don’t take certain actions.
At my company, I typically have to join at least three tables: one for whatever type of action I’m looking at, one for the company, and one for what type of software the company has. That way I can filter out test accounts and look at companies with the particular product I have in mind.
Each table should have one column that has unique values for each rows (a ‘primary key’). In my example, each fruit name is unique.
Other tables then include those same values so the tables can be tied together.
Let’s say I also have a table with some information with other fruit information. I want to be able to figure out how many fruits I have in my inventory that are in season in fall.
Table name: fruit_info
| info_name | season | genus |
| strawberry | summer | fragaria |
| pineapple | fall | ananas comosus |
| apple_r | fall | malus pumila |
| apple_y | fall | malus pumila |
| apple_g | fall | malus pumila |
| figs | fall | ficus carica |
Here’s the basic idea, where the columns that are being matched after ON are the records that are the same across the tables.
FROM table1 t1 INNER JOIN table2 t2 ON t1.column=t2.column;
So to get a list of all fruits and inventory counts that are in season in fall, we could do:
SELECT f.name, f.inventory_count, fi.season FROM fruits f INNER JOIN fruit_info fi ON f.name=fi.info_name WHERE fi.season='fall';
| f.name | f.inventory_count | fi.season |
| pineapple | 10 | fall |
| apple_r | 5 | fall |
| apple_y | 3 | fall |
| apple_g | 2 | fall |
Note that figs don’t show up on the list. That’s because I’m using INNER JOIN. Only items that are on BOTH lists are going to show up with inner join. In this case, that’s most useful for this query, since figs wouldn’t have any inventory count, so I don’t want it to show.
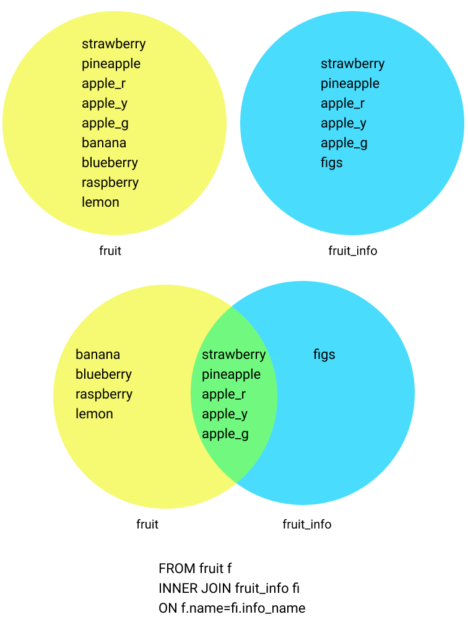
When you have multiple tables, it’s best to give each a nickname that you can use to refer to it throughout the rest of your query.
I don’t technically need the f. and fi. above before the column names, because the column names are distinct. But in situations where you have the same column name in multiple tables, you need to clarify which one you are talking about.
Did you find this useful? Interested in learning more?
I may do another post with some useful examples of dealing with time, since that’s a critical consideration for product managers – how usage/sign-up rates are changing over time.
P.S. Special thanks to Samantha (my kid) for helping review this! She says it all makes sense to her 🙂